Liferay search debugging
Liferay by default uses Lucene as the indexing and search engine. Lucene index is stored either in a file system (as the default option) or in database tables in distributed environments.
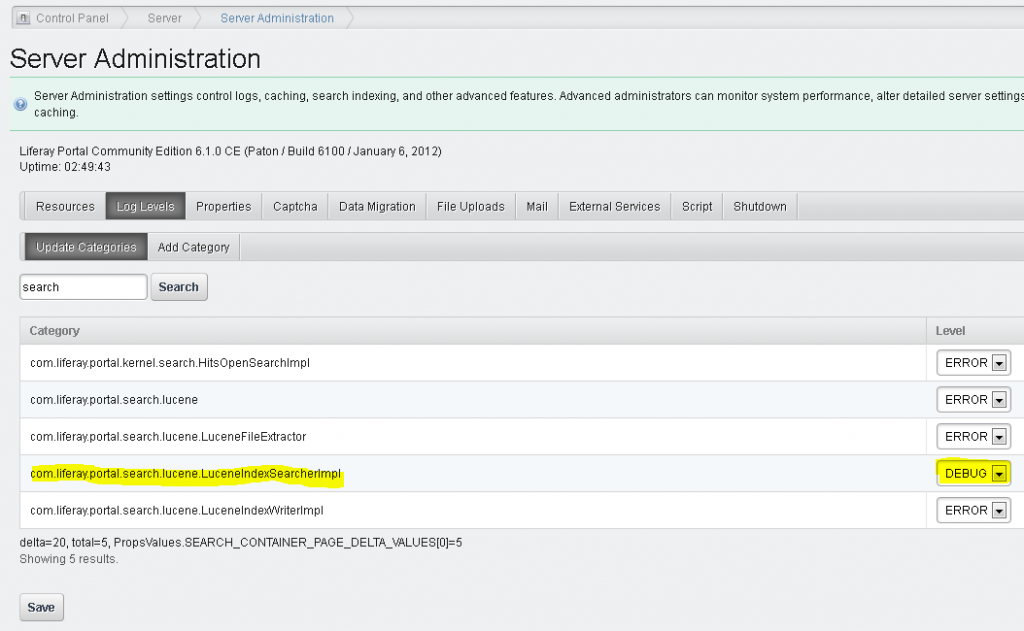
The first thing to check is to display the search query. This can be accomplished by activation of the search query display in the search portlet itself, or by activating an appropriate debug level on the portal instance.
How to activate search debug on portal instance
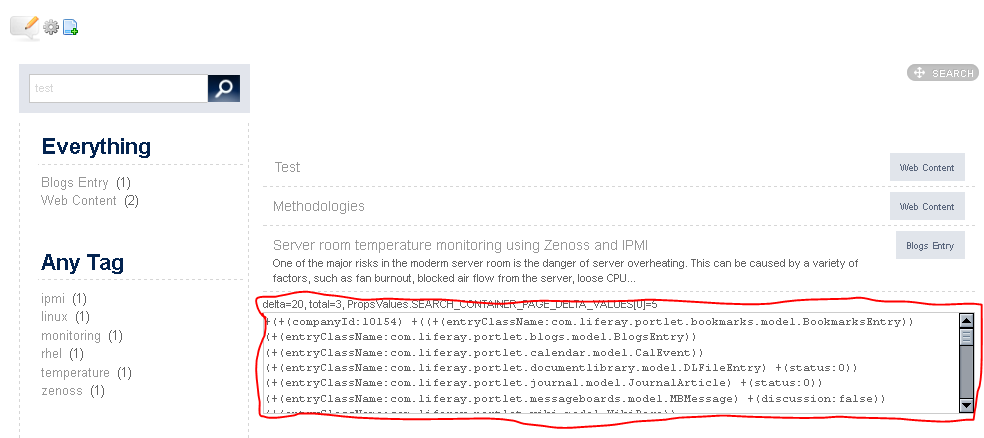
Result in the log file is a complete search dump of the query and results:
18:08:37,712 DEBUG [LuceneIndexSearcherImpl:192] Query +(+(companyId:10154) +((+(entryClassName:com.liferay.portlet.bookmarks.model.BookmarksEntry)) (
+(entryClassName:com.liferay.portlet.blogs.model.BlogsEntry)) (+(entryClassName:com.liferay.portlet.calendar.model.CalEvent)) (+(entryClassName:com.li
feray.portlet.documentlibrary.model.DLFileEntry) +(status:0)) (+(entryClassName:com.liferay.portlet.journal.model.JournalArticle) +(status:0)) (+(entr
yClassName:com.liferay.portlet.messageboards.model.MBMessage) +(discussion:false)) (+(entryClassName:com.liferay.portlet.wiki.model.WikiPage)) (+(entr
yClassName:com.liferay.portal.model.User) +(status:0))) +(+(groupId:10180) +(scopeGroupId:10180))) +(assetCategoryNames:test assetTagNames:test commen
ts:test content:test description:test properties:test title:test url:test userName:test ddm/13001/ClimateForcast_PROGRAM_ID:test ddm/13001/ClimateForc
ast_COMMAND_LINE:test ddm/13001/ClimateForcast_HISTORY:test ddm/13001/ClimateForcast_TABLE_ID:test ddm/13001/ClimateForcast_INSTITUTION:test ddm/13001...18:08:37,794 DEBUG [LuceneIndexSearcherImpl:594] 4.0 = (MATCH) sum of:
1.0 = (MATCH) sum of:
0.0 = (MATCH) fieldWeight(companyId:10154 in 165), product of:
1.0 = tf(termFreq(companyId:10154)=1)
1.0 = idf(docFreq=230, maxDocs=230)
0.0 = fieldNorm(field=companyId, doc=165)
1.0 = (MATCH) sum of:
1.0 = (MATCH) sum of:
0.0 = (MATCH) fieldWeight(entryClassName:com.liferay.portlet.journal.model.JournalArticle in 165), product of:
1.0 = tf(termFreq(entryClassName:com.liferay.portlet.journal.model.JournalArticle)=1)
1.0 = idf(docFreq=103, maxDocs=230)
0.0 = fieldNorm(field=entryClassName, doc=165)
1.0 = (MATCH) fieldWeight(status:0 in 165), product of:
1.0 = tf(termFreq(status:0)=1)
...(the complete output is not shown here)
How to activate debug on search portlet
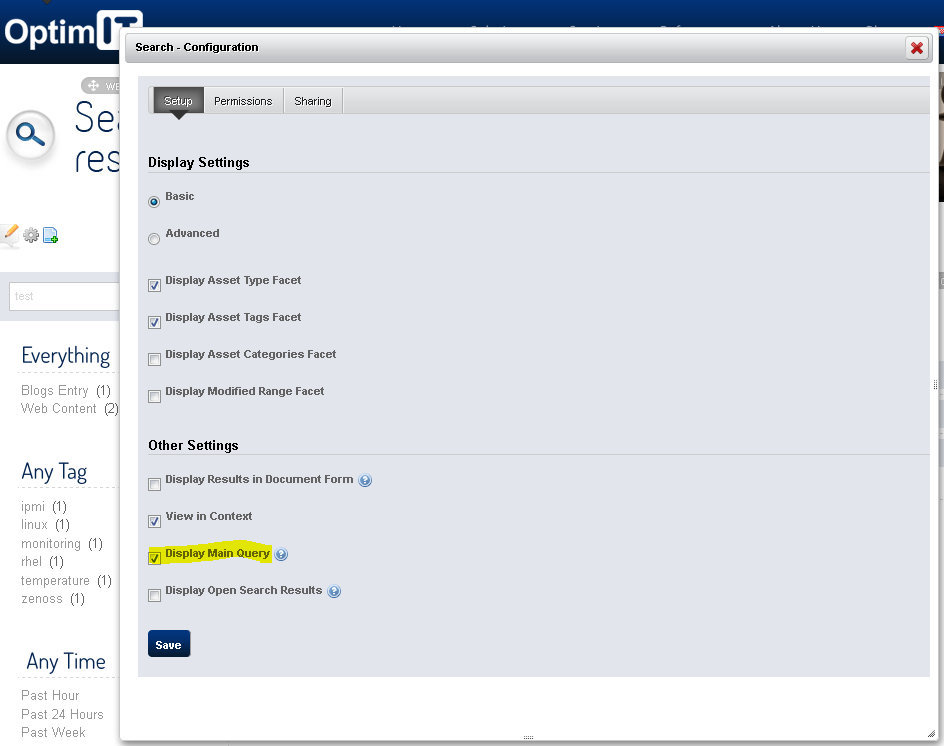
Compare results with Lucene index
Once we have the search query, we can examine it and try to modify it or run it directly “on” the Lucene index. This is accomplished by a small tool called Luke. Luke is used to analyze, query and optimize Lucene index. It can be downloaded from: http://www.getopt.org/luke/. It comes in few flavors (standalone, of just Luke code which then uses Lucene libraries from portal installation).
To run the complete version, do following:
java -jar lukeall-3.5.0.jarThis will start Luke and display the following screen. On the given screen select a directory of your index (usually in the portal data directory, named as a code of your site e.g. 10185). Open the index as read only if the portal instance is currently running.
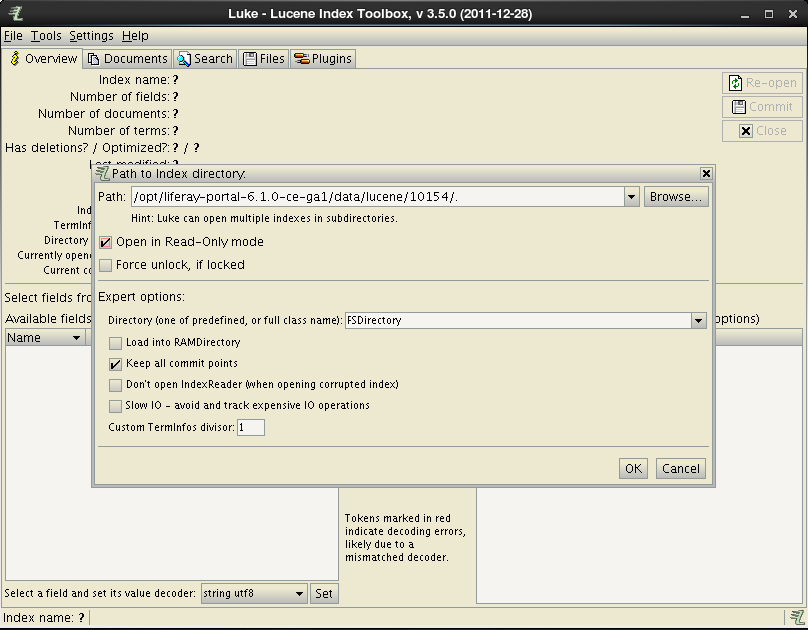
With Luke you have the opportunity to see what gets indexed in the portal instance, to run desired query and to check object data returned by that query. (Other functionalities provided by Luke are not covered here).
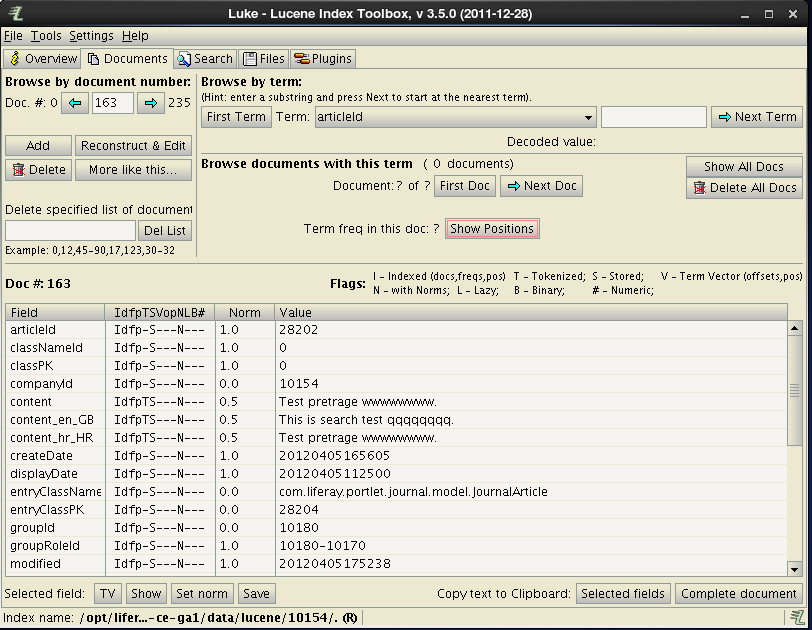
The overview screen provides a possibility to browse the indexed data, to see the top terms and the general index information. This is useful for checking if the indexing engine is correctly configured. For example – if English terms are indexed in non English fields, that will result in the mixed language of the generated search results. Another example are Croatian fields such as content_hr_HR containing words like “i”, “a”, “ne”, “za”…, which indicate that so called “stop words” are not taken into account for the given language.
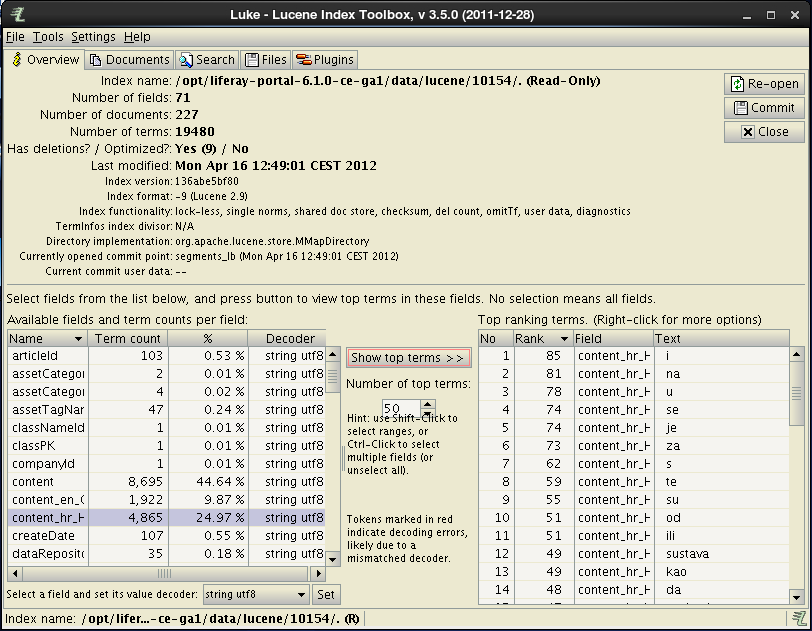
The search tab provides an opportunity for testing search queries directly on given index (through the Lucene search engine). This is accomplished on the search tab.
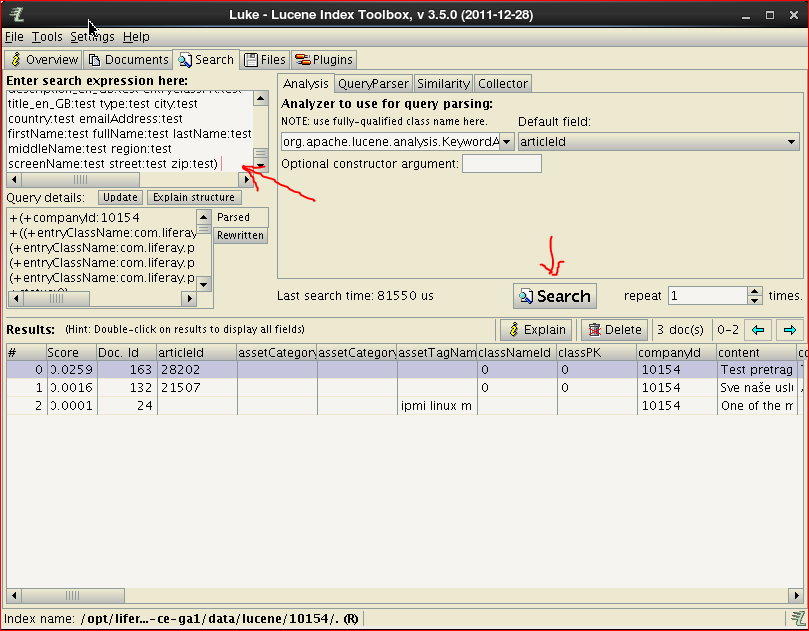
The returned results can be examined on this tab or in the document details by double clicking one of the documents. The documents detail tab brings the complete document that was passed to the indexing engine with extra information on all fields (regarding their indexing type). A typical document is shown below:
Using described tools and technics it is possible to follow search process from the server to the index engine and back again in order to find out why some of the results are shown (although not expected) and why other expected results are not shown.